Most weeks of the course have a lecture and a lab. In the lecture you are introduced to material, and in the lab you use Python to solve problems using that material.
These notebooks act as a bridge between the lecture and the lab. Each one summarises the lecture, and provides code examples as a starting point for writing your own code. In the first few notebooks, I will import packages on-the-fly as needed so you can see when they are required. In the later notebooks, and in the labs, imports will be done at the start.
These notebooks start off relatively light for the first few weeks and get heavier when we get to the machine learning part of the course (Week 5 onwards).
The first lecture was slightly unusual, in that it was also an introduction to the course. I am not going to summarise the introduction (whatever that would entail) but I am going to look at different data modalities, and how you can process them in Python.
1.2 Data modalities
1.2.1 Time series
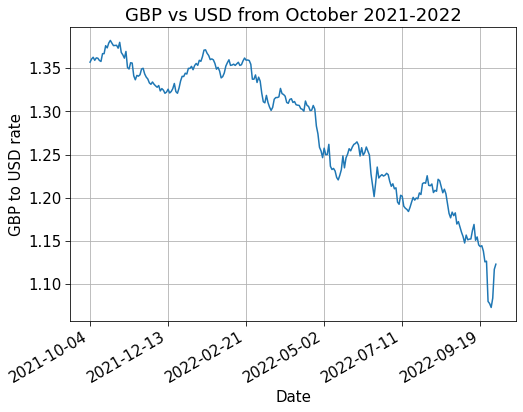
In time series data, we have some quantity we care about at different points in time. We are going to consider the value of the pound (GBP) vs. the dollar (USD). A lot of the time we import our data from spreadsheets (e.g. excel files, CSV files) and this is no exception!
I have already downloaded the spreadsheet containing GBP vs. USD values from 04/10/2021 to 03/10/2022 from Yahoo Finance which is in CSV format.
How do we get this into Python? There is a fantastic data analysis library called pandas which does all the hard work for us.
# Import pandas for dataframesimport pandas as pd# Read CSV into dataframe using pandasdf = pd.read_csv("data/GBPUSD=X.csv")# Show dataframedf
Date
Open
High
Low
Close
Adj Close
Volume
0
2021-10-04
1.357092
1.363977
1.353363
1.357092
1.357092
0
1
2021-10-05
1.360766
1.365001
1.358585
1.360748
1.360748
0
2
2021-10-06
1.362565
1.363141
1.354463
1.362769
1.362769
0
3
2021-10-07
1.359268
1.363736
1.357184
1.359213
1.359213
0
4
2021-10-08
1.361953
1.365374
1.358493
1.362027
1.362027
0
...
...
...
...
...
...
...
...
256
2022-09-27
1.077006
1.083541
1.073849
1.077284
1.077284
0
257
2022-09-28
1.072846
1.083964
1.054163
1.072754
1.072754
0
258
2022-09-29
1.083459
1.106562
1.076449
1.083600
1.083600
0
259
2022-09-30
1.116184
1.123394
1.102682
1.116944
1.116944
0
260
2022-10-03
1.118456
1.127485
1.108672
1.122914
1.122914
0
261 rows × 7 columns
Let’s say we care about the closing value at the end of each day. This is in the Close column. We can plot this against Date using a few lines of code.
# matplotlib for plottingimport matplotlib.pyplot as plt# This makes matplotlib output nice figures without much tweakingplt.rcParams.update( {"lines.markersize": 10, # Big points"font.size": 15, # Larger font"xtick.major.size": 5.0, # Bigger xticks"ytick.major.size": 5.0, # Bigger yticks })# Plotting codefig, ax = plt.subplots(figsize=[8,6])ax.plot(df["Date"], df["Close"])ax.set_xlabel('Date')ax.set_ylabel('GBP to USD rate')ax.set_title('GBP vs USD from October 2021-2022')# Add a gridax.grid()# Formatting specifically for date stringsfig.autofmt_xdate()# A hacky way of showing a subset of x ticksdates = df["Date"].to_numpy()ax.set_xticks([dates[i] for i inrange(0, len(dates), 50)])
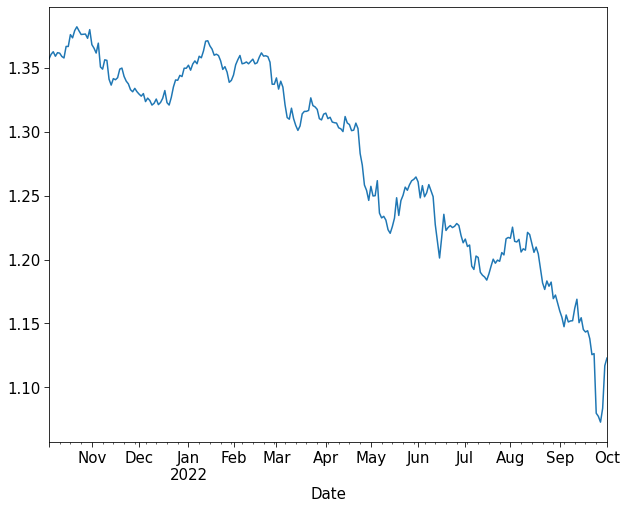
There is an alternative way to do this just in pandas. Notice that each row has an index (0,1,2,3…). We can turn the Date column into a datetime format, and then make that the index instead. We can then just call .plot on the dataframe to plot a column against the date index.
Let’s do all this on a copy of the original dataframe:
We can also take a column and convert it into a numpy array. Let’s take the Close column, convert it into an array, and find its mean. (This can be done directly in pandas but is for illustration!)
# import numpy for arraysimport numpy as npclose_array = df["Close"].valuesclose_mean = np.mean(close_array)print(f"The mean close value is {close_mean:3f}")
The mean close value is 1.280153
1.2.2 Tabular data
We actually did just extract our time series data from tabular data! Tabular data will make up the vast majority of data you look at in this course. It is very common in the real world.
Let’s say we want the list of dates for which the opening value of GBP vs. USD was greater than 1.3.
PIL (the Python imaging library) lets us read in images, as well as perform high-level manipulations. We will load in a JPEG of a dog, and also print the image size in pixels.
# Image from PIL lets us manipulate imagesfrom PIL import Image# Read imageimage = Image.open("data/dog.jpg")# Use Juypter's inbuilt display functiondisplay(image)print(f"The image has a size of {image.size}")
The image has a size of (615, 615)
We can downsize the image…
image = image.resize((224, 224))display(image)
and rotate it!
image = image.rotate(90)display(image)
Recall from the lectures that an image is actually stored as a 3D array (height by width by colour channel). We can see this if we convert our image into a numpy array.
# Convert image into a numpy arraydata_im = np.array(image)# See what the array looks like and print its shapeprint(data_im)print(f"the image in numpy has shape {data_im.shape}")
Let’s manually set the red colour channel to zero for all pixels and see what happens.
# Create a copy of our image arraydata_nored = data_im.copy()# Set all values in the red channel to 0data_nored[:, :, 0] =0# Now we have a numpy array we have to use matplotlib to display itplt.imshow(data_nored)
Without any red, the blue and green have got more … blue and green. This wasn’t the most obvious manipulation! Try some others by changing the code above.